La web hoy en día se ha vuelto un ecosistema donde las personas cada vez más se mueven mucho más naturalmente a través de las diversas interacciones que se dan en este complejo ambiente. Los usuarios finales navegan, suben archivos, hacen consultas, realizan búsquedas, en fin, las interfaces de la web cada vez son más comunes a los ojos de las personas, que esa sensación de tiempos antiguos de que todo lo que tenía que ver con computadoras era super complejo, y solo los "nerds" lo entendían, esta prácticamente en extinción.
Para aquellos que nos ganamos la vida produciendo “1’s y 0’s” para que otros usuarios puedan seguir habitando el mundo de la web, resultamos ser un poco más orgullosos porque podemos “jactarnos” que conocemos algunas capas más abajo del subsuelo de la web. Pero la verdad es que la web es tan compleja que los mismos desarrolladores, debido a las herramientas que nos hemos acostumbrado a usar, somos muchas veces grandes desconocedores de todo lo que sucede más allá de las capas superficiales de la web.
En este post, que es más una traducción libre del capítulo 1 del libro
Struts 2 In Action: “Struts 2: the modern web application framework" (Struts 2: el framework de aplicaciones web moderno), quiero describir algunos puntos básicos que todo ingeniero de la web, particularmente el ingeniero que desarrolla aplicaciones web en la plataforma de Java, debería conocer. Examinaremos la pila tecnológica sobre la cual los frameworks de aplicaciones se montan para poder ocultar y facilitar todas esas funciones, que de lo contrario harían la vida muy difícil a los desarrolladores.
La pila tecnológica
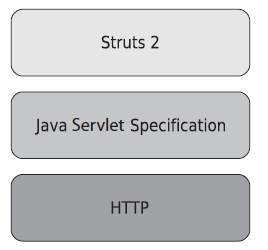
En una manera muy resumida, según lo muestra la figura, los frameworks de aplicación (de Java) se sitúan sobre dos tecnologías importantes: el protocolo HTTP y la especificación de servlets de java.
La API de Servlet maneja todas las comunicaciones de bajo nivel con la capa HTTP. En tiempos modernos no es considerado una buena práctica programar usando directamente la API, pero conocer lo básico de ella nos ayuda a entender mejor la arquitectura sobre la cual construimos nuestras aplicaciones.
Ya que se menciona el protocolo HTTP, cabe destacar los conceptos básicos que se encierran en este protocolo tan común en nuestra vida diaria. Sin él no podríamos hacer ningún tipo de navegación en Internet. El protocolo HTTP es un protocolo que no guarda estado. Consiste en una serie de mensajes entre un cliente, típicamente un navegador, y un servidor, que puede ser una web o aplicación web, por medio de los cuales se solicitan distintos tipos de datos que al final se despliegan para un usuario. Cabe mencionar que el protocolo HTTP no fue originalmente pensado para considerar la cantidad de información compleja e interacciones de usuarios que ahora se utilizan actualmente en la Internet. Este es un tipo de problema que las aplicaciones web deben solucionar en tiempos modernos.
Debido a la falta de estado entre las peticiones, y al hecho de que todas las peticiones son basadas en texto plano, las aplicaciones web deben ingeniárselas para resolver esa brecha resultante de seguir trabajando sobre un protocolo que fue pensado para servir documentos HTML. Los casos de uso más complicados, como una simple validación de usuario, sería como programar en ensamblador (bueno, tal vez no tanto) si no tuviéramos la ayuda de los frameworks web. Otro detalle quizás desapercibido a la hora de utilizar un framework como Struts es la conversión de datos en la comunicación. Esto se vuelve bastante transparente para la mayoría de los desarrolladores. El protocolo es muy tieso en su comunicación por medio de texto plano, mientras que Java es un lenguaje altamente tipeado. Si tuviéramos que pensar todo el tiempo en nuestras aplicaciones web como convertir texto a entero, por dar un ejemplo, pasaríamos menos tiempo resolviendo los verdaderos casos de uso de la aplicación, y más tiempo haciendo tareas repetitivas y aburridas.
La Java Servlet API
La API de Servlets de Java da un paso más adelante para resolver la gran complejidad de lidiar directamente con el protocolo HTTP. Por medio de la API un programador Java puede interactuar con el protocolo usando una encapsulación en el típico paradigma de programación orientación a objetos. Es por ello que en la API hayamos objetos como el HTTPRequest o el HTTPResponse. En síntesis la API permite recibir requests HTTP, incluyendo los parámetros del query string y datos de formularios, hacer un proceso back-end, y retornar una respuesta al usuario. Todo a traves de código Java.
La unidad básica de empaquetamiento de un servlet se conoce como una aplicación web. Aunque parece una definición simple, esto tiene un sentido en el contexto de servlets. La especificación de servlets define una aplicación web como una colección de servlets, páginas HTML, clases, y otros recursos. Típicamente, una aplicación web requiere de más de un servlet para satisfacer todas las solicitudes de sus clientes. Los servlets y recursos de una aplicación web son empacados en una estructura de directorio estándar y nombrado con una extensión .war. Un archivo WAR es una versión especializada de un archivo .jar. Significa archivo de aplicación web (Web Application Archive).
Una vez que se tiene este archivo web empaquetado, hay que desplegarlo (deploy) en un contenedor de servlets. El servlet es un tipo especial de aplicación llamado aplicación manejada por ciclo de vida. En este tipo de aplicación uno no ejecuta directamente el servlet sino que el contenedor es el encargado de ejecutar el servlet a través de sus métodos de ciclo de vida, donde el principal es el llamado service(). Cuando una solicitud llega al contenedor, este primero determina cuál servlet es el que tiene que usarse para satisfacerla.
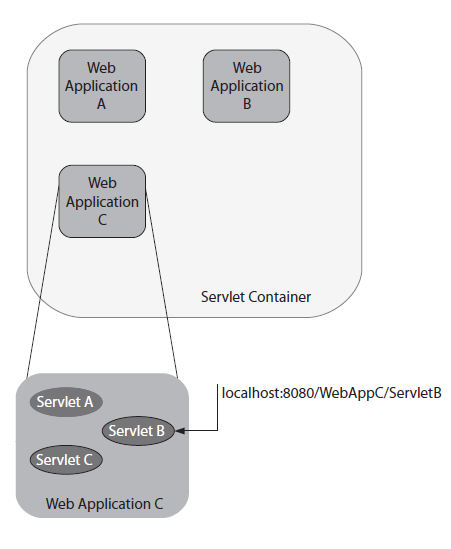
En la siguiente figura se muestra un contenedor con tres aplicaciones web y como a través de una URL se determina cual aplicación y servlet debe satisfacer la solicitud
Otra funcionalidad que agrega la API es la capacidad de manejar sesiones. Como se había mencionado, el protocolo HTTP no tiene estado, lo cual significa que no se puede correlacionar las distintas solicitudes a un servidor con un cliente específico. Sino fuera por la API, habría que ingeniarselas con el uso de galletas y llaves de sesión empotradas en el query string para poder mantener una sesión activa con un usuario específico. Aparte de esta funcionalidad, la API no provee más funciones adicionales, pero es el fundamento a partir del cual se construyen sólidas aplicaciones web, incluyendo los frameworks.
Siguiente nivel
Habiendo entendido, de una manera sintetizada, cuáles son las labores de bajo nivel de la API de servlets, podemos entonces continuar con las tareas que no son tomadas en cuenta por la API, y que por tanto son los frameworks web los que suministran estas capacidades a los desarrolladores.
Ligación (binding) de los parámetros de la solicitud (request) y validación de datos.
Recordamos de nuevo que los parámetros del request viajan en texto plano en el protocolo HTTP, y la API de servlets no provee un proceso automático de conversión a distintos tipos de variables en Java. Puede que esto no sea algo extremadamente complejo de implementar por cuenta de un desarrollador, pero es lo suficientemente repetitivo y monótono como para no dejarlo como una funcionalidad de un framework. La necesidad de la validación de datos es obvio de entender para cualquier desarrollador. El framework lo que permite es definir una manera estructurada y consistente para la validación de formularios.
Llamados a las capas de lógica de negocio y datos
Esta es una de las facultades que no son específicas de una aplicación web. Cualquier aplicación sin importar si es web o de escritorio necesita manejar un tipo de flujo de trabajo donde una solicitud de usuario pasa por las capas de presentación, lógica de negocio y acceso a base de datos, y luego viceversa para enviar la respuesta. Este flujo representa algún tipo de tarea que debe completarse. En algunos frameworks web como Struts, a estas tareas se le conoce como acciones, y el framework es conocido como un framework orientado a acciones.
Renderizacion e internacionalizacion
Lejos estamos de los días aquellos del comienzo de la web donde utilizabamos páginas simples construidas en HTML. Cada vez más los sitios web son mucho más complejos en su interfaz para dar una experiencia mucho más rica al usuario. Tecnologías como Ajax, HTML5 y la creciente penetración de los dispositivos móviles, hacen que sea necesario el soporte de un framework para aliviar la complejidad de la capa de presentación.
Agregado a esto tenemos la necesidad de la internacionalización que es la capacidad de una aplicación de adaptar varios elementos de la misma para acomodarse a una región, país o localidad. Ejemplo simples son el texto desplegado para cambiar a un idioma según el país, el formato de la hora y fecha, la moneda, etc. Ciertamente esto es algo que buscamos que un framework nos lo probea.
¿Qué es un framework?
Un framework es una pieza de software estructural. Se dice que es estructural porque la estructura es quizás la meta principal del framework, más que cualquier otro requerimiento funcional. Un framework trata hacer generalizaciones acerca de las tareas comunes y el flujo de trabajo de un dominio específico. El framework entonces intenta proveer una plataforma sobre la cual las aplicaciones de un dominio pueden ser construidas de manera rapida y eficaz. El framework hace esto de dos maneras principales. Primero, el framework trata de automatizar todas aquellas tareas tediosas del dominio. Segundo, el framework intenta introducir una solución arquitectural elegante al flujo de trabajo común del dominio en cuestión.
En una sola definición podemos decir que un framework es una pieza de software estructural que provee automatización de tareas comunes al dominio, así como una incorporación de una solución arquitectural que puede ser fácilmente extendida por aplicaciones que implementan el framework.
¿Por qué utilizar un framework?
Uno necesariamente no tiene la obligación de utilizar un framework, pero pensar en la alternativas que son omitir el uso de un framework, o crear uno propio, realmente acarrea más desventajas que beneficios.
En el primer caso, al menos que sea una aplicación sea sencilla, el hecho de tener que implementar todas las tareas tediosas y repetitivas del dominio en cuestión, resulta en un código altamente complejo y difícil de mantener, sin mencionar que cansado y agotante. Lo ideal en un proyecto de desarrollo de software es gastar la mayor cantidad de esfuerzo en tareas de alto nivel acorde con el negocio, en lugar de invertirlas en reinventar el agua tibia.
En el segundo caso, son muy limitados los escenarios donde es necesario tener que desarrollar un framework desde cero en lugar de utilizar uno existente, principalmente porque deben darse varias raras condiciones en disponibilidad de recursos: desarrolladores sumamente hábiles, tiempo y dinero, todo esto para gastarlo en un proyecto en primera instancia, sin retorno de inversión a corto o mediano plazo. Y aún si estas condiciones se dan, siguen habiendo desventajas con esta estrategia. Hay que invertir tiempo y dinero en preparar nuevos desarrolladores en una solución local, mientras que si se utiliza un framework popular se pueden contratar desarrolladores ya entrenados. Además los frameworks caseros tienden a erosionarse con el tiempo, mientras que los modernos se mantienen en continua actualización.
Sin duda los frameworks web son casi mandatorios para cualquier proyecto de desarrollo web en la actualidad, sin embargo conocer los pilares de las soluciones web nos ayudan a entender mejor la arquitectura para solucionar los problemas que no son triviales, como rendimiento y escalabilidad.